Generating a Clinical Instruction Dataset in Portuguese with Langchain and GPT-4

In this article, we’ll explore the process of creating a high-quality instruction-following dataset using OpenAI’s GPT-4 model, assisted by the Langchain library, based on the same approach used to generate the Alpaca dataset (https://huggingface.co/datasets/tatsu-lab/alpaca).
Introduction
Fine-tuning Large Language Models (LLMs) for specific use cases has become a hot topic in the AI community. The likes of OpenAI’s GPT-3, and its successor, GPT-4, have shown tremendous potential in understanding and generating human-like text, making them powerful tools for various applications in natural language processing. However, to leverage their full potential in a particular domain or application, fine-tuning them on a custom dataset is often necessary.
Understanding Instruction Datasets
An instruction dataset typically comprises a set of diverse task instructions meant to guide an AI model’s behavior. For our purpose, we will be considering instructions in Portuguese, not exceeding 1 to 2 sentences in length. They could be either questions or imperative sentences. Our aim is to achieve a dataset with maximum diversity, without repetition of verbs and language structure. The final dataset should ideally involve realistic data, limiting the use of simple placeholders.
The Steps to Generating an Instruction Dataset
The process of generating an instruction dataset can be broken down into four major steps, each involving different tasks and requiring different tools. In this section, we’ll go through each of these steps in detail, offering practical insights and code snippets.
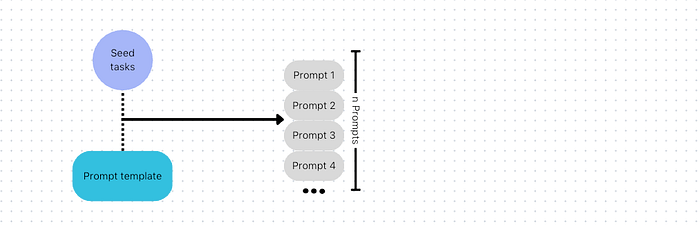
1. Preparing Your Seed Tasks
Before you can start generating your instruction dataset, you first need a set of seed tasks. These tasks, which typically come in the form of instructions followed by corresponding inputs and outputs, serve as the foundation for your dataset generation process. They are used to provide context and prompt the LLM into generating further tasks.
2. Creating a Prompt Template
After preparing your seed tasks, the next step involves encoding these tasks into a specific format that can be used by Langchain chains.
3. Mixing Seed Tasks and Format the Final Prompts
After your prompt template have been suitably created, the next crucial step is to develop a pipeline that will randomly take seed instructions and format them into your prompt template resulting in a set of final prompts that will instruct the LLM to generate new examples.
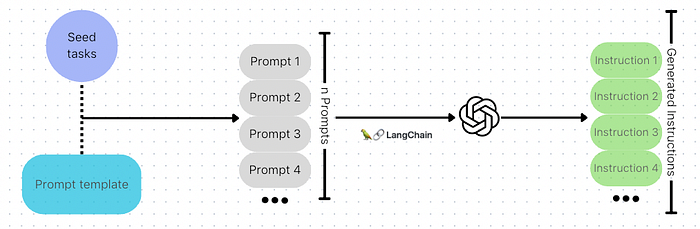
4. Generating and Processing Instructions
With the setup out of the way, we can now focus on the core part of the process: generating and processing instructions. This involves sending your encoded prompts to the LLM and processing the received responses into a suitable format for your instruction dataset.
By following these steps, you will be able to leverage Langchain and GPT-4 to generate a comprehensive instruction dataset that can be used to fine-tune your Large Language Model to better suit your specific needs.
Step 1 — Format Your Seed Tasks
For this tutorial, we prepared a dataset containing 17 pairs of instructions related to the clinical domain in Brazilian Portuguese. We first created a .csv file with columns for instruction, input, and output. Then, we read this file into a pandas DataFrame and transformed the DataFrame into a list of JSON objects. This list was then saved to a .json file in a format suitable for being passed as prompts to GPT-4.
Here is the Python code we used for this transformation:
Example seed instruction from our dataset:
Step 2 — Install Requirements and Import Libraries
Before diving into coding, we must ensure we have the necessary Python libraries installed and imported into our workspace. These libraries provide various functionalities, ranging from numerical operations to language modeling and from scoring systems to data visualization.
2.1 Installing Libraries
Below is the list of libraries we will be using throughout this project:
numpy: For numerical operations.rouge_score: For evaluating the quality of text generation.openai: For interacting with the OpenAI API.transformers: For utilizing transformer models.torch: For using PyTorch deep learning framework.sentencepiece: For text tokenization.tokenizers: For efficient tokenization, encoding, and decoding.langchain: For creating our LLM Chain.
Use the following pip command to install the necessary libraries:
2.2 Importing Libraries
Once the necessary libraries are installed, you can import them in your Python script. The import command will differ depending on the library. Below are the general import commands for the required libraries:
Step 3 — Define the Functions
After installing and importing the necessary libraries, we will now define a number of functions that will be used in the code. Below are the descriptions of these functions and their respective code:
3.1 Encode Prompt Function
This function takes the prompt instructions as input and encodes them into a single string that can be understood by the GPT-4 model.
3.2 Post-process GPT-4 Response Function
The post_process_gpt3_response function is designed to take the raw output from the language model and format it in a way that is more usable for downstream tasks. It's used to extract and format the generated instructions from the model's output. It performs several checks and filters to ensure the quality and relevance of the instructions. Below are the steps this function performs:
- Checking the response: The function first checks if the response is None. If it is, it immediately returns an empty list.
- Splitting the response: The response is then divided by “###” into separate sections. Each section represents a separate instruction generated by the model.
- Extracting instructions, input, and output: The function then loops over these sections and for each one, it separates the instruction, input, and output by splitting the section text using regular expressions. It ensures that these three elements are present and correctly formatted. If the section does not contain exactly 7 elements after splitting (which corresponds to three pairs of instructions, input, and output, plus the remaining text), it is ignored.
- Filtering the instructions: Next, the function applies several filters to the instructions:
- Length check: Instructions that are too short (less than or equal to 3 words) or too long (more than 150 words) are filtered out. This ensures the instructions are meaningful and not overly complex.
- Keyword check: Instructions that contain certain keywords (e.g., “image”, “graph”, “file”, “map”, “go to”, “video”, etc.) are also filtered out. These keywords are chosen based on the nature of the task and the limitations of the language model (e.g., a language model can’t process images or videos).
- Specific phrase check: If the instruction starts with “Write a program”, it is discarded. This is because such instructions can lead to confusion whether the model needs to output a program code or directly provide the result.
- Punctuation check: Instructions starting with punctuation are filtered out as they’re likely to be incomplete or malformed.
5. Appending instructions: If an instruction passes all these filters, it is appended to a list of instructions in the form of a dictionary with keys “instruction”, “input”, and “output”. This list is returned by the function.
By running the post-processing function, the raw output from the language model is transformed into a list of instructions that are easier to work with for the next steps of the program. It also ensures that the instructions are of a certain quality and fit the requirements and constraints of the given task.
3.3 Helper Functions for File Operations
These are helper functions for performing read and write operations on JSON files.
3.4 String Processing Functions
These are helper functions for processing strings.
3.5 Generate Instruction Following Data Function
The generate_instruction_following_data function is a bit complex, as it serves as the main driver for the entire instruction generation process. Here's a breakdown of what it does:
- Loading the seed tasks: The function starts by loading a set of seed tasks from a JSON file. These seed tasks are human-written instructions used to guide the language model’s instruction generation.
- Preparing the data: The loaded data is then transformed into a list of dictionaries where each dictionary contains an instruction, input, and output from the seed tasks.
- Preparing the directories and files: The function then checks if a directory for the output exists and if not, creates it. It also checks if there are any pre-existing machine-generated instructions from previous runs of the function. If such instructions exist, they are loaded and used in the current run
- Creating a scorer: The Rouge scorer is created, which will be used later to compute the similarity between the generated instructions and the existing ones.
- Creating the language model: The function then initializes an instance of the
ChatOpenAIclass, which is used to generate instructions. The OpenAI's GPT-4 model is used for the task. - Instruction Generation: This is where the main action takes place. The function enters a while loop that continues until a specified number of instructions have been generated. In each iteration:
- The function selects a number of random instructions from the seed tasks, encodes them into a prompt, and feeds this prompt into the language model to generate new instructions.
- The generated instructions are post-processed using the
post_process_gpt3_responsefunction discussed earlier.
7. Filtering and processing generated instructions: The function then iterates over each generated instruction:
- It first computes the Rouge-L score between the new instruction and all existing instructions. If the highest score is above 0.7 (i.e., the new instruction is very similar to an existing one), the instruction is discarded.
- If the instruction is sufficiently unique, it is appended to the list of machine-generated instructions. Other metadata, such as the average similarity score and the most similar instructions, are also stored for future reference.
8. Saving the generated instructions: After generating and processing all the instructions in a batch, the function dumps the machine instructions into a JSON file. This allows the instructions to be saved and used in future runs of the function.
9. Repeating the process: The function repeats the instruction generation, post-processing, and saving process until it generates the desired number of instructions.
The generate_instruction_following_data function, therefore, encapsulates the entire process of generating new instructions from seed tasks using a language model, processing and filtering those instructions, and saving them for future use.
Step 4 — Formatting Your Prompt Template
Our prompt template looked like this stated the following requirements:
- Don’t repeat the same verb for each instruction to maximize diversity.
- The language used in the instruction should also be diverse. For example, you should mix questions with imperative instructions.
- The type of instructions should be diverse. The list should include different types of tasks such as open generation, classification, editing, etc.
- A GPT-based AI should be capable of completing the instruction. For example, do not ask the AI to create any visual or audio output. Similarly, don’t ask the AI to wake you up at 5 pm or set a reminder, as it can’t perform any action.
- All instructions and inputs should be in Portuguese.
- The instructions should be concise, with 1–2 sentences. An imperative sentence or a question are allowed.
- You should generate an appropriate input for the instruction. The input field should contain a specific example provided for the instruction. It should involve realistic data and should not contain simple placeholders. The input should provide substantial content to make the instruction challenging, but ideally should not exceed 100 words.
- Not all instructions require input. For example, when an instruction asks for some general information, “what is the highest peak in the world”, there is no need to provide a specific context. In this case, we simply put “<noinput>” in the input field.
- The output should be an appropriate response to the instruction and input.
Step 5— Generating the Dataset
Now that we have the necessary functions defined, let’s start generating the dataset. We’ll use the generate_instruction_following_data function to create the dataset using the GPT-4 model. You need to supply an OpenAI API key to use GPT-4.
Here is the configuration we’ll use for our dataset generation:
- The output directory (
output_dir) is set to "./new_tasks". This is where our generated tasks will be stored. - The seed tasks path (
seed_tasks_path) is set to "./seed_tasks.json". This file contains the initial set of tasks that we'll use to guide the generation process. - We’ll generate 15 instructions (
num_instructions_to_generate). - The model used for generation (
model_name) is GPT-4. - For each prompt, we’ll use 3 instructions from the seed tasks (
num_prompt_instructions). - We’ll generate instructions in batches of 5 (
request_batch_size). - The temperature (
temperature) for the generation process is set to 0. This means the generation process will be deterministic, and will always choose the most likely next token when generating text. - The
top_pparameter is set to 1.0, meaning we won't use nucleus sampling in the generation process. - The number of CPUs (
num_cpus) used for parallel processing is set to 4.
Here is the Python code for this step:
When you run the above code, it starts the dataset generation process using the configurations you have set. After the function has finished running, you will find the generated tasks in the “new_tasks” directory. You can then use this generated dataset for various purposes, such as training and evaluating language models on instruction following tasks.
Please ensure you have enough quota and necessary permissions from OpenAI to access GPT-4 for generating the dataset.
Final Thoughts and Analysis
The two JSON outputs below represent a sample of the final processed output of the model. They demonstrate the versatility of the model in creating diverse tasks, as well as the model’s ability to generate relevant input-output pairs.
Let’s analyze each example in detail:
1. Example 1:
Instruction: “Explique a diferença entre um resfriado comum e a gripe.”
The model successfully generates an explanation detailing the differences between a common cold and the flu.
Most Similar Instructions: The system identifies similar instructions based on its training data and scores them. It’s clear that the model has found related tasks that involve symptom analysis, explaining medical test results, or creating patient records — which are similar processes to explaining differences between diseases.
Average Similarity Score: This score is quite low (0.06), which shows that the given instruction is fairly unique compared to other tasks the model has learned.
2. Example 2:
Instruction: “Identifique os medicamentos mencionados no texto.”
The model correctly identifies the medications mentioned in the input text.
Most Similar Instructions: The model correctly associates this instruction with tasks like finding diagnoses in the text, identifying warning signs, and classifying medical test results, which are related to the task of identifying medications.
Average Similarity Score: The average similarity score here is higher (0.11), implying that this task is more common or similar to other tasks in the model’s training data.
The diversity of task instructions and corresponding input-output pairs demonstrates the potential for this pipeline.
Concluding Remarks
We hope this comprehensive guide has provided you with a solid foundation for creating instruction datasets using the GPT model and Langchain. Although we’ve focused on medical tasks, the process can be applied to various other domains.
You can find the complete code for this guide on my GitHub repository. For a more interactive experience, you can run the code on this Google Colab notebook.
Next Steps
Having generated our clinical instruction dataset, our journey doesn’t end here. We have exciting plans on the horizon. The next phase of this project will involve leveraging this generated dataset to fine-tune an open-source language model.
By leveraging the distinctiveness and diversity of our generated dataset, we aim to create a model that is finely attuned to the intricacies of clinical instructions in the Portuguese language. This model would be designed to handle the diversity of language expressions and the richness of medical terminology captured in the data.
Our focus on using an open-source model underscores our commitment to the broader AI community. By sharing our fine-tuned model, we hope to pave the way for further innovation and exploration in the realm of multilingual AI and healthcare.
Stay tuned as we embark on this exciting new phase of our project. We’re looking forward to seeing what we can achieve with our newly minted Portuguese clinical instruction dataset and the power of open-source AI.